Introduction to Apache Hadoop
Hadoop is an open source project from the Apache foundation that was created thinking that hardware components in a network are prone to failure and that there should be a component handling those failures automatically in a way that does not create downtime for the system or affects the users in any way. Hadoop is mainly written in Java and it can run on the main operating systems. It was originally created by Doug Cutting while he was working on Yahoo. It was named after a toy elephant that belongs to Doug’s son.
The ever-growing need of data storage is also a big part of the Hadoop inception. In this day and age, a company storing user data cannot afford to lose any of it due to hardware failures. Just imagine getting an email saying “We just lost all your photos/messages/work/art/portfolio/reports/money because one of our servers failed. Sorry!”. That is simply unacceptable, and Hadoop was created to prevent that problem.
Just the task of storing that data is an enormous challenge. Being responsible for handling sensitive data in large amounts can be very intimidating. Just imagine being the architect of a successful startup that suddenly is required to not store and handle Gigabytes, but Terabytes, or even Petabytes of data. And more importantly, you are required to do it in a manner that is secure, cheap, fast, easy, scalable, and failure-proof. How would you accomplish that? Requesting larger and larger budgets for servers and hard-drives, all of them having a life-span of a few months? Or would you prefer to use commodity hardware with a framework that handles all that for you? If you chose the later, Hadoop may be the answer. Hadoop is the software component that allows the IT infrastructure to grow organically and easily when it needs to do it. It prevents individual hardware failures to cause any real impact to the IT services and, ultimately, to the user experience.
Not convinced yet? What if I told you that you can use Hadoop to do parallel processing and leverage all that combined horsepower from your commodity hardware? We will talk about how Hadoop accomplishes all these wonderful things later, but for now, let’s talk about the main Hadoop components.
Hadoop components
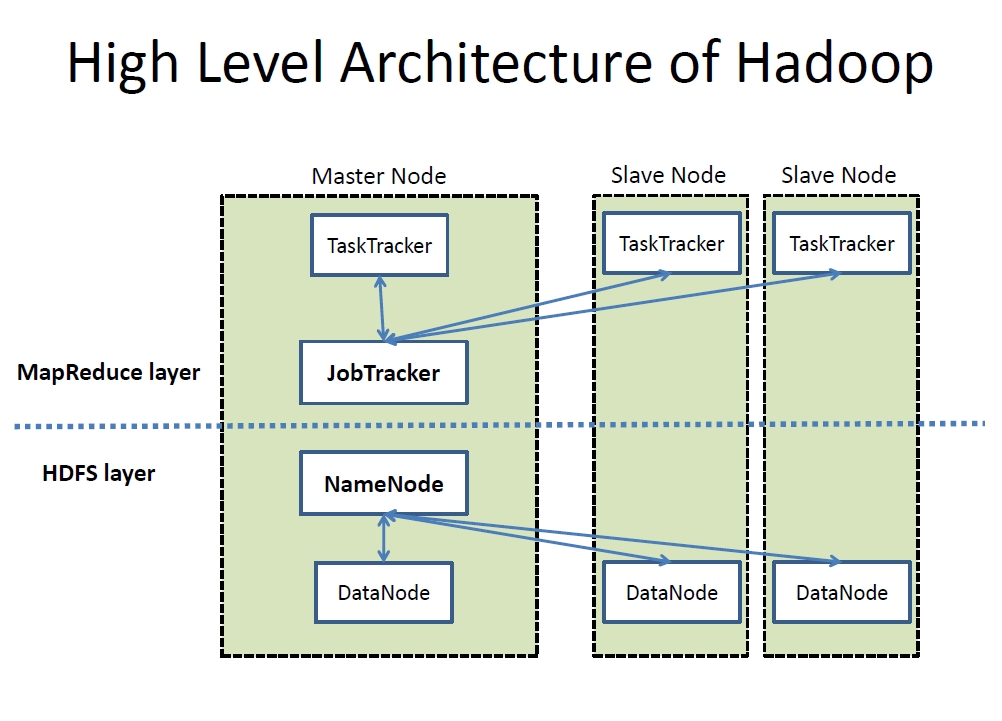
Hadoop has two main components, not counting the Hadoop core functionality and YARN (Yet Another Resource Negotiator, a resource-management platform responsible for managing computing resources in clusters). These two main components are MapReduce and HDFS.
MapReduce is a framework for performing calculations on the data in the distributed file system. With MapReduce, applications can process vast amounts (multiple terabytes) of data in parallel on large clusters in a reliable, fault-tolerant manner. MapReduce uses one “JobTracker” node, to which applications submit MapReduce jobs. The JobTracker “maps” or assigns work and pushes it out to available “TaskTracker” nodes in the cluster, striving to keep the work as close to the data as possible. Each TaskTracker performs the required processing and then the results are retrieved by the JobTracker node (this is the “reduce” part).
The distributed filesystem component, the main example of which is HDFS (Hadoop Distributed File System), though other file systems, such as IBM GPFS-FPO, are supported. In HDFS, there is a “NameNode” keeping track of all the locations of all the data across the cluster. The other nodes are called “DataNodes” and store the data in “blocks” of information. The same blocks are copied in several DataNodes (generally in another DataNode in the same rack and also in another DataNode in a different rack). Obviously, the higher the data redundancy in the cluster, the safer the data is in case one or several DataNodes go down or suffer irreparable damage. A Hadoop user can easily specify the amount of replication that is needed and customize the way the blocks are handled.
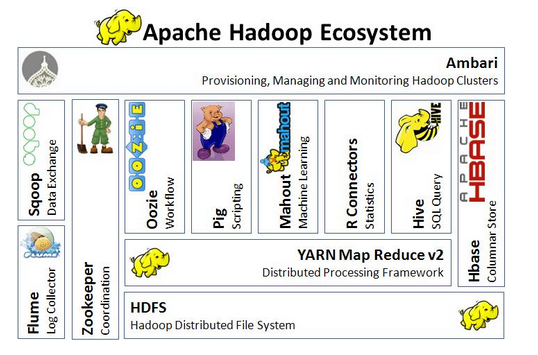
Related projects
Due to its potential and usefulness, Hadoop is one of the most famous projects related to big data and it has inspired many related projects. Many implementations of Hadoop use some (or many) of these projects in order to build a robust ad-hoc infrastructure. Some of them are:
Ambari: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually along with features to diagnose their performance characteristics in a user-friendly manner.
Avro: A data serialization system.
Cassandra: A scalable multi-master database with no single points of failure.
Chukwa: A data collection system for managing large distributed systems.
Flume: A distributed, reliable, and highly available service for efficiently moving large amounts of data around a cluster.
HBase: A non-relational, scalable, distributed database that supports structured data storage for large tables.
Hive: A data warehouse infrastructure that provides data summarization and ad-hoc querying.
Jaql: A query language designed for JavaScript Object Notation (JSON), is primarily used to analyze large-scale semi-structured data. It is an open source project from Google, IBM took it over as primary data processing language for their Hadoop software package BigInsights (see the “Hadoop and IBM” section below).
Mahout: A Scalable machine learning and data mining library.
Oozie: A workflow coordination manager.
Pig: A high-level data-flow language and execution framework for parallel computation.
Spark: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation. I will also be talking about Spark very soon.
Sqoop: A command-line interface application for transferring data between relational databases and Hadoop.
Tez: A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. Tez is being adopted by Hive, Pig and other frameworks in the Hadoop ecosystem, and also by other commercial software (e.g. ETL tools), to replace Hadoop MapReduce as the underlying execution engine.
ZooKeeper: A high-performance coordination service for distributed applications.
Who is using Hadoop?
Take a look at the “Powered by” page at the Hadoop site and the Hadoop page in Wikipedia. You will notice a very large list of important names and some very impressive numbers. For example, on June of 2010, Facebook announced to store 100 Petabytes of its data on Hadoop clusters, and on November 8 of 2012, they announced the data gathered in their warehouse grows by roughly half a Petabyte per day.
Yahoo is by far the largest contributor to Hadoop, and there is a good reason for that. Yahoo Mail uses Hadoop to find spam. The Yahoo front page as well as the links and ads displayed to every user are both optimized using Hadoop.[1] Yahoo contributes all the work it does on Hadoop to the open-source community.
Besides contributors to the Hadoop environment, the usage is widely spread among other companies which are merely users. Proof of that is that more than half of the Fortune 50 use Hadoop.[2]
Hadoop and IBM
IBM is aware of the potential in Hadoop and is leveraging it in some of its projects. For example, Watson uses IBM’s DeepQA software and the Apache UIMA (Unstructured Information Management Architecture) framework. The system was written in various languages, including Java, C++, and Prolog, and runs on the SUSE Linux Enterprise Server 11 operating system using the Hadoop framework to provide distributed computing.[3] Hadoop enables Watson to access, sort, and process data in a massively parallel system (90+ server cluster/2,880 processor cores/16 terabytes of RAM/4 terabytes of disk storage).[4]
IBM BigInsights is a platform for the analysis and visualization of Internet-scale data volumes. It is powered by Hadoop and it offers makes easier to install and administer Hadoop cluster using a web GUI. BigInsights makes it trivial to start and stop Hadoop services and adding, removing nodes to the cluster.
In 2009, IBM discussed running Hadoop over the IBM General Parallel File System.[5] The source code was published in October 2009.[6]
Conclusion
Supporting Hadoop will be critical in the near future. The advantages it offers are too many to just ignore it. As the use of big data grows (alongside with customer’s expectations), most companies will inevitably gravitate to Big Data, Hadoop and/or Hadoop-related technologies in the near future. This is probably not a end-user facing technology like a mobile application or a website, but Hadoop is already ingrained in the back-end of many popular services like Facebook, Twitter, Yahoo, Linkedin, Spotify and many others.
In other words, Hadoop is not a prototype technology anymore, it is already an integral part of the infrastructure for live production applications with millions of concurrent users. Being capable to understand and support Hadoop and all the related technologies will be essential for any IT team very soon, because either clients will request it or it will be a necessity for the internal operations of the organization itself.
References:
- https://developer.yahoo.com/blogs/hadoop/ll-hadoop-400-alex-3901.html
- http://www.prnewswire.com/news-releases/altiors-altrastar—hadoop-storage-accelerator-and-optimizer-now-certified-on-cdh4-clouderas-distribution-including-apache-hadoop-version-4-183906141.html
- https://en.wikipedia.org/wiki/Watson_%28computer%29
- https://blogs.apache.org/foundation/entry/apache_innovation_bolsters_ibm_s
- https://www.usenix.org/legacy/events/hotcloud09/tech/full_papers/ananthanarayanan.pdf
- https://issues.apache.org/jira/browse/HADOOP-6330