Introduction to Apache Spark
 Spark is an open source cluster computing framework widely known for being extremely fast. It was started by AMPLab at UC Berkeley in 2009. Now it is an Apache top-level project. Spark can run on its own or can run, for example, in Hadoop or Mesos, and it can access data from diverse sources, including HDFS, Cassandra, HBase and Hive. Spark shares some characteristics with Apache Hadoop but they have important differences. Spark was developed to overcome the limitations of Hadoop’s MapReduce in regards of iterative algorithms and interactive data analysis.
Spark is an open source cluster computing framework widely known for being extremely fast. It was started by AMPLab at UC Berkeley in 2009. Now it is an Apache top-level project. Spark can run on its own or can run, for example, in Hadoop or Mesos, and it can access data from diverse sources, including HDFS, Cassandra, HBase and Hive. Spark shares some characteristics with Apache Hadoop but they have important differences. Spark was developed to overcome the limitations of Hadoop’s MapReduce in regards of iterative algorithms and interactive data analysis.
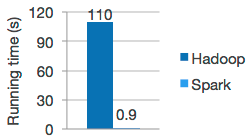
Since the very beginning, Spark showed great potential. Soon after its creation, Spark was already showing that it was being ten or twenty times faster than MapReduce for certain jobs. If is often said that it can be as 100 times faster, and this has been proven many times. For that reason, it is now widely used in areas where analysis is fundamental, like retail, astronomy, biomedicine, physics, marketing, and of course, IT. Thanks to this, Spark has become synonymous with a new term: “Fast data”. This means having the capability to process large amounts of data as fast as possible. Let’s not forget Spark’s motto and raison d’être: “Lightning-fast cluster computing”.
Spark can efficiently scale up and down using minimal resources, and developers enjoy a more concise API, which helps them be more productive. Spark supports Scala, Java, Python, and R. While it also offers interactive shells for Scala and Python.
Components:
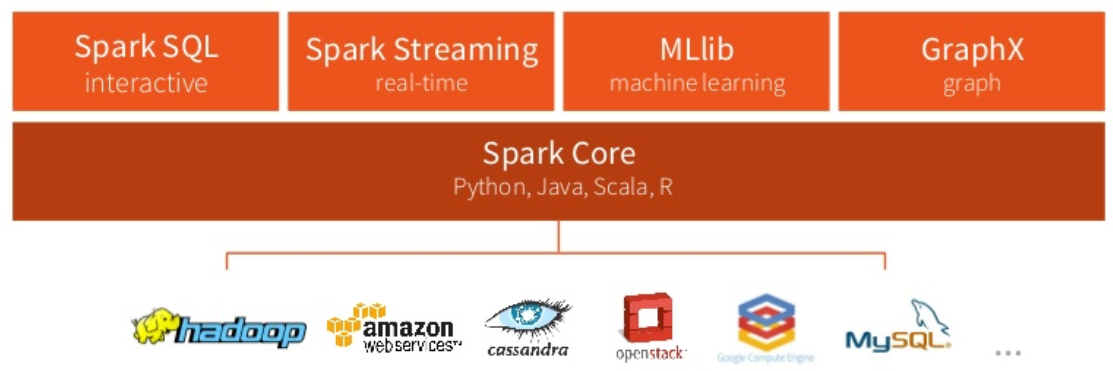
Spark can recover failed nodes by recomputing the Directed Acyclic Graph (DAG) of the RDDs, and it also supports a recovery method using “checkpoints”. This is a clever way of guaranteeing fault tolerance that minimizes network I/O. RDDs achieve this by using lineage, i.e. if an RDD is lost, the RDD has enough information about how it was derived from other RDD (i.e. the DAGs are “replayed”), so it can be rebuilt easily. This works better than fetching data from disk every time. In this way, fault tolerance is achieved without using replication.
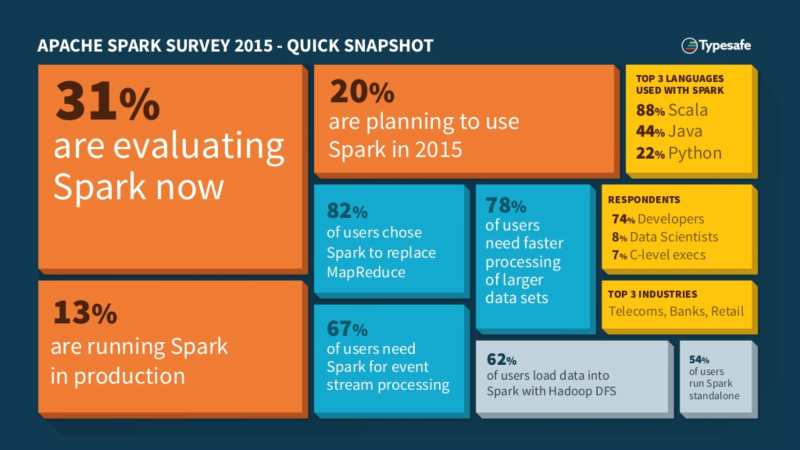
Spark usage metrics:
In late December 2014, Typesafe created a survey about Spark, and they noticed a “hockey-stick-like” growth in its use[1], with many people already using Spark in production or planning to do it soon. The survey reached 2,136 technology professionals. These are some of their conclusions:
So, is Spark better than Hadoop? This is a question that is very difficult to answer. This is a topic that is frequently discussed, and the only conclusion is that there is no clear winner. Both technologies offer different advantages and they can be used alongside perfectly. That is the reason why the Apache foundation has not merged both projects, and this will likely not happen, at least not anytime soon. Hadoop reputation was cemented as the Big Data poster child, and with good reason. And for that, with every new project that emerges, people wonder how it relates to Hadoop. Is it a complement for Hadoop? A competitor? An enabler? something that could leverage Hadoop’s capabilities? all of the above?
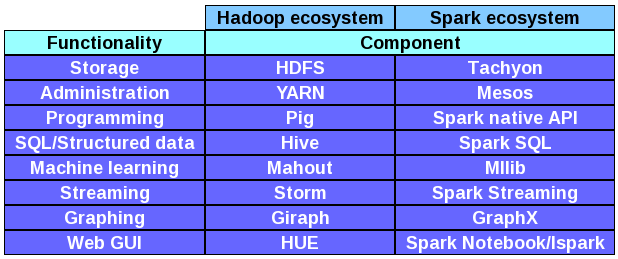
As you can see in the table above, Spark offers a lot of functionality out of the box. If you wanted to build an environment with the same capabilities, you would need to install, configure and maintain several projects at the same time. This is one of the great advantages in Spark: having a full-fledged data engine ready to work out of the box. Of course, many of the projects are interchangeable. For example, you could easily use HDFS for storage instead of Tachyon, or use YARN instead of Mesos. The fact that all of these are open source projects means they have a lot of versatility, and this means the users can have many options available, so they can have their cake and eat it. For example, if you are used to program in Pig and want to use it in Spark, a new project called Spork (you got to love the name) was created so you can do it. Hive, Hue, Mahout and many other tools from the Hadoop ecosystem already work or soon will work with Spark.[2]
Let’s say you want to build a cluster, and you want it to be cheap. Since Spark uses memory heavily, and RAM is relatively expensive, one could think that Hadoop MapReduce is cheaper, since MapReduce relies more on disc space than on RAM. However, the potentially more expensive Spark cluster could finish the job faster precisely because it uses RAM heavily. So, you could end up paying a few hours of usage for the Spark cluster instead of days for the Hadoop cluster. The official Spark FAQ page talks about how Spark was used to sort 100 TB of data three times faster than Hadoop MapReduce on 1/10th of the machines, winning the 2014 Daytona Graysort Benchmark[3].
If you have specific needs (like running machine learning algorithms, for example) you may decide over one technology or the other. It all really depends of what you need to do and how you are paying for resources. It is basically a case-by-case decision. Neither Spark nor Hadoop are silver bullets. In fact, I would say that there are no silver bullets in Big Data yet. For example, while Spark has streaming capabilities, Apache Storm generally is considered better at it.
Real-world use-cases:
There are many ingenious and useful examples of Spark in the wild. Let’s talk about some of them.
IBM has been working with NASA and the SETI Institute using Spark in order to analyze 100 million radio events detected over several years. This analysis could lead to the discovery of intelligent extraterrestrial life. [4] [5] [6]
The analytic capabilities of Spark are also being used to identify suspicious vehicles mentioned in AMBER alerts. Basically, video feeds are entered into a Spark cluster using Spark Streaming, then they are processed with OpenCV for image recognition and MLlib for machine learning. Together, they would identify the model and color of cars. Which in turn could help to find missing children.[4] Spark’s speed here is crucial. In this example, huge amounts of live data need to be processed as quickly as possible and it also needs to be done continually, i.e. processing as the data is being collected, hence the use of Spark Streaming. [7]
Warren Buffet created an application where social network analysis is performed in order to predict stock trends. Based on this, the user of the application gets recommendations from the application about when and how to buy, sell or hold stocks. It is obvious that a lot of people would be interested in suggestions like this, and specially when they are taken from live, real data like Tweets. All this is accomplished with Spark Streaming and MLlib.[4]
Of course, there is also a long list of companies using Spark for their day-to-day analytics, the “Powered by Spark” page has a lot of important names like Yahoo, eBay, Amazon, NASA, Nokia, IBM Almaden, UC Berkeley, TripAdvisor, among many others.
Take, for example, mapping Twitter activity based on streaming data. In the video below you can see a Spark Notebook that is consuming the Twitter stream, filtering the tweets that have geospatial information and plotting them on a map that is narrowing the view to the minimal bounding box enclosing the last batch’s tweets. It is very easy to imagine the collaboration that streaming technologies and the Internet of Things will end up doing. All that data generated by IoT devices will need to be processed and streaming tools like Spark Streaming and/or Apache Storm will be there to do the job.
Conclusion:
Spark was designed in a very intelligent way. Since it is newer, the architects used the learned lessons from other projects (mainly from Hadoop). The emergence of the Internet of Things is already producing a constant flow of large amounts of data. There will be a need to gather that data, process it and draw conclusions on it. Spark can do all of this and do it blindingly fast.
IBM has shown a tremendous amount of interest and commitment to Spark. For example, they founded the Spark Technology Center in San Francisco, enabled a Spark-As-A-Service model on Bluemix, and organized Spark hackatons[8]. They also committed to train more than 1 million of data scientists, and donated SystemML (a machine learning technology) to further advance Spark’s development [9]. That doesn’t happen if an initiative doesn’t have support at the highest levels of the company. In fact, they have called it “potentially, the most significant open source project of the next decade”. [10]
All this heralds a bright future for Spark and the related projects. It is hard to imagine how the project will evolve, but the impact it has already done in the big data ecosystem is something to take very seriously.
References:
[1] http://www.slideshare.net/Typesafe_Inc/sneak-preview-apache-spark
[2] http://es.slideshare.net/sbaltagi/spark-or-hadoop-is-it-an-eitheror-proposition-by-slim-baltagi
[3] https://spark.apache.org/faq.html
[4] http://www.spark.tc/projects/
[5] http://blog.ibmjstart.net/2015/07/14/seti-sparks-machine-learning-to-sift-big-data/
[6] http://blog.ibmjstart.net/2015/08/06/types-of-bigdata-from-the-allen-telescope-array/
[7] https://github.com/hackspark/Amber-Alert-Aid
[8] http://blog.ibmjstart.net/2015/06/29/why-is-ibm-involved-with-apache-spark/
[9] http://www.ibm.com/analytics/us/en/technology/spark/
[10] https://www-03.ibm.com/press/us/en/pressrelease/47107.wss